
I. インフィニバンド・ネットワークとは何か?
InfiniBand(通称「IB」)は、ネットワーク通信規格であり、RDMA(リモート・ダイレクト・メモリ・アクセス)技術を実装するプロトコルのひとつです。高速差動信号技術と多チャネル並列伝送メカニズムを採用しており、その主な目的は「高性能、低遅延、高信頼性」を実現することにあります。
InfiniBandは、サーバー分野におけるハイパフォーマンス・コンピューティング(HPC)専用の相互接続技術です。極めて高いスループットと非常に低いレイテンシを特徴とし、コンピュータ間のデータ相互接続(レプリケーションや分散ワークロードなど)に利用されます。 また、InfiniBandは、サーバーとストレージシステム(SANやダイレクトアタッチドストレージなど)間、およびストレージシステム同士の直接接続やスイッチ接続としても採用されています。 さらに、サーバーとネットワーク(LAN、WAN、インターネットなど)間の通信も容易にします。データセンターやHPC/ストレージ分野で広く利用されています。その後、人工知能(AI)の台頭に伴い、GPUサーバーを接続するためのネットワーク相互接続技術として主流となっています。
II. InfiniBandの発展の歴史
1990年代初頭、インテルは増え続ける外部デバイスに対応するため、標準的なPCアーキテクチャへのPCIバス設計の導入を先駆けて行いました。しかし、CPU、メモリ、ハードドライブ、その他のコンポーネントが急速に進化するにつれ、PCIバスの進化の遅さがシステム全体のボトルネックとなってしまいました。 この問題に対処するため、コンパック、デル、HP、IBM、インテル、マイクロソフト、サン・マイクロシステムズをはじめとするIT業界の主要企業と、その他180社以上の企業が共同で**IBTA(InfiniBand Trade Association)**を設立しました。
IBTAの目的は、PCIに代わる新たな代替技術を研究し、その伝送ボトルネックの問題を解決することにありました。 その結果、2000年に**InfiniBandアーキテクチャ仕様バージョン1.0**が正式にリリースされた。これにはRDMAプロトコルが導入され、低遅延、大帯域幅、高信頼性を実現し、I/O性能を飛躍的に向上させたことで、システム相互接続技術の新たな標準として確立された。
InfiniBandといえば、どうしてもあるイスラエルの企業――**Mellanox**(中国名:、覚えやすい略称は「ネジを売る」)が思い浮かびます。 1999年5月、インテルとガリレオ・テクノロジーの元従業員数名によってイスラエルで設立されたメラーノックスは、設立直後にインフィニバンド業界団体に加盟しました。2001年には、同社初のインフィニバンド製品を発売しました。
2002年、InfiniBand陣営は大きな変革に直面した。インテルは「船を降りる」ことを決め、開発の焦点を2004年に発表された**PCI Express (PCIe)**に移すことにした。 もう一つの巨人であるマイクロソフトも、InfiniBandの開発から撤退した。サンや日立といった企業は引き続き関与していたものの、InfiniBandの将来は不透明なものとなった。
2003年以降、InfiniBandは「コンピュータ・クラスタの相互接続」という新たな応用分野へと軸足を移しました。 2005年には、「ストレージデバイスの接続」という新たな用途も見出されました。2012年以降、ハイパフォーマンス・コンピューティング(HPC)の需要が継続的に拡大したことを受け、InfiniBand技術は飛躍的な発展を遂げ、着実に市場シェアを拡大していきました。
InfiniBand技術が徐々に注目を集めるにつれ、Mellanoxも成長を遂げ、やがて"業界のトップ企業" InfiniBand分野において。2010年、MellanoxはVoltaireと合併し、その結果、Mellanox(2019年にNVIDIAに買収)とQLogic(2012年にIntelに買収)が主要なInfiniBandサプライヤーとなった。
2013年、メラノックスはシリコンフォトニクス技術企業であるコトゥラと、並列光インターコネクトチップメーカーのIPトロニクスを買収し、業界における事業ポートフォリオをさらに強化した。
2015年、InfiniBand技術のシェアは"TOP500" スーパーコンピュータランキングで、その割合が初めて50%を超えた。これにより、InfiniBandは初めてイーサネット技術を追い抜き、"スーパーコンピュータ向けの推奨クラスタ相互接続技術".
2015年までに、メラーノックスは"80%のシェア" 世界のInfiniBand市場において。同社の事業範囲はチップから、ネットワークアダプタ、スイッチ/ゲートウェイ、遠隔通信システム、ケーブル/モジュールに至るまで全領域へと拡大し、世界トップクラスのネットワークプロバイダーとしての地位を確立した。
2019年、NVIDIAはMellanoxを買収するという大きな動きを見せ、"69億ドル"。NVIDIAのCEOであるジェンセン・フアン氏は次のように述べた。「これは、ハイパフォーマンス・コンピューティング分野における世界トップクラスの2社の融合です。NVIDIAはアクセラレーテッド・コンピューティングに注力し、Mellanoxは相互接続とストレージに注力しています。」 今振り返れば、NVIDIAは驚くべき先見の明を示していたと言える。大規模モデルのトレーニングは高性能コンピューティング・クラスターに大きく依存しており、InfiniBandネットワークは"最適なパートナー" そのようなクラスターについて。
III. InfiniBandの仕組み
ネットワークの専門家以外の方にとって、InfiniBandの動作原理は複雑に思えるかもしれません。初心者は基本を把握するか、このセクションを飛ばしても構いません。InfiniBandプロトコルもまた、"階層型アーキテクチャ"各層は独立しており、その上の層に対してサービスを提供します。
物理層:物理リンク上でビット信号がシンボルに、さらにフレーム、データシンボル、およびパケット間のデータフィラーに組み立てられる方法を規定する。また、有効なパケットを構築するためのシグナリングプロトコルなどを詳細に規定する。
リンク層:データパケットのフォーマットや、フロー制御、ルーティング、符号化、復号化などのパケット処理に関するプロトコルを規定する。
ネットワーク層:パケットに40バイトのグローバルルートヘッダー(GRH)を追加することでルーティングを実行する。転送の際、ルーターは可変CRCチェックのみを行い、"エンドツーエンドのデータ伝送の完全性".
トランスポート層:パケットを特定のキューペア(QP)に配信し、そのQPに対してパケットの処理方法を指示します。 InfiniBandネットワークトランスポートは、データ伝送の信頼性と効率性を確保するために、クレジットベースのフロー制御(CBFC)技術を採用しています。このメカニズムは、送信側と受信側の間でクレジット(受信側が受け入れ可能なデータ量を表す)を管理し、パケット損失や輻輳を防止します。
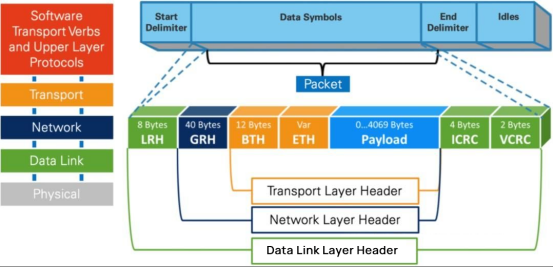
QP(キューペア)は、RDMA技術における基本的な通信単位です。これは、SQ(送信キュー)とRQ(受信キュー)という2つのキューのペアで構成されています。ユーザーがAPIを呼び出してデータを送信または受信する際、実質的にそのデータをQPに格納することになります。 QP内のリクエストは、その後ポーリング方式で1つずつ処理されます。
の利点"CBFC" この技術は、主に以下の3つの点に要約できます:
1. 輻輳の回避:動的な帯域幅調整とロスレス伝送により、CBFCはネットワークの輻輳やパケットロスを効果的に防止します。
2. 効率の向上:送信側は、クレジットが枯渇するまで確認応答を待たずにデータを継続的に送信できるため、データ転送の効率が向上する。
3.自動設定:InfiniBandデバイスを物理的に設置すると、フロー制御メカニズムが自動的に有効になるため、ユーザーによる手動設定は不要です。
明らかなように、InfiniBandは独自のレイヤー1~4(物理層、リンク層、ネットワーク層、トランスポート層)のフォーマットを定義しており、完全なネットワークプロトコルを構成しています。エンドツーエンドのフロー制御は、InfiniBandネットワークパケットの送受信の基盤となっており、極めて効率的なロスレスネットワークの実現を可能にしています。
もちろん、InfiniBandの高速度かつロスレスなネットワークを実現するには、Socket Direct、Adaptive Routing、サブネット管理のためのSubnet Manager(SM)、ネットワークパーティショニング、そしてネットワーク最適化のためのSHARP(Scalable Hierarchical Aggregation and Reduction Protocol)エンジンといった技術や機能も不可欠です。 これらのコンポーネントが一体となって、InfiniBandの特徴である高いパフォーマンス、低遅延、そして容易なスケーラビリティを実現しています。






