
AI大規模モデルのトレーニング、高性能コンピューティング、クラウドコンピューティングの急速な発展に伴い、企業のサーバーに対するGPU演算能力およびストレージ性能への需要は爆発的な成長傾向を示しています。 しかし、従来のサーバーアーキテクチャには、PCIeスロットの数に限りがあること、GPUとSSDの配置のバランスが取りにくいこと、拡張ソリューションの柔軟性に欠けることなど、拡張能力において多くのボトルネックが存在します。これらの問題は、ビジネスのイノベーションを著しく阻害してきました。本稿では、こうした業界の課題を深く分析し、LR-LINKがどのように LRSV9500-4I 柔軟なX4/X8/X16の分岐モードを通じて、企業にワンストップの拡張ソリューションを提供します。
I. PCIeスロットリソースの深刻な不足
1.1 現状
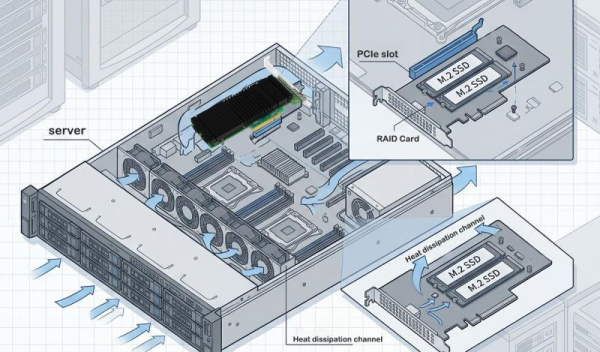
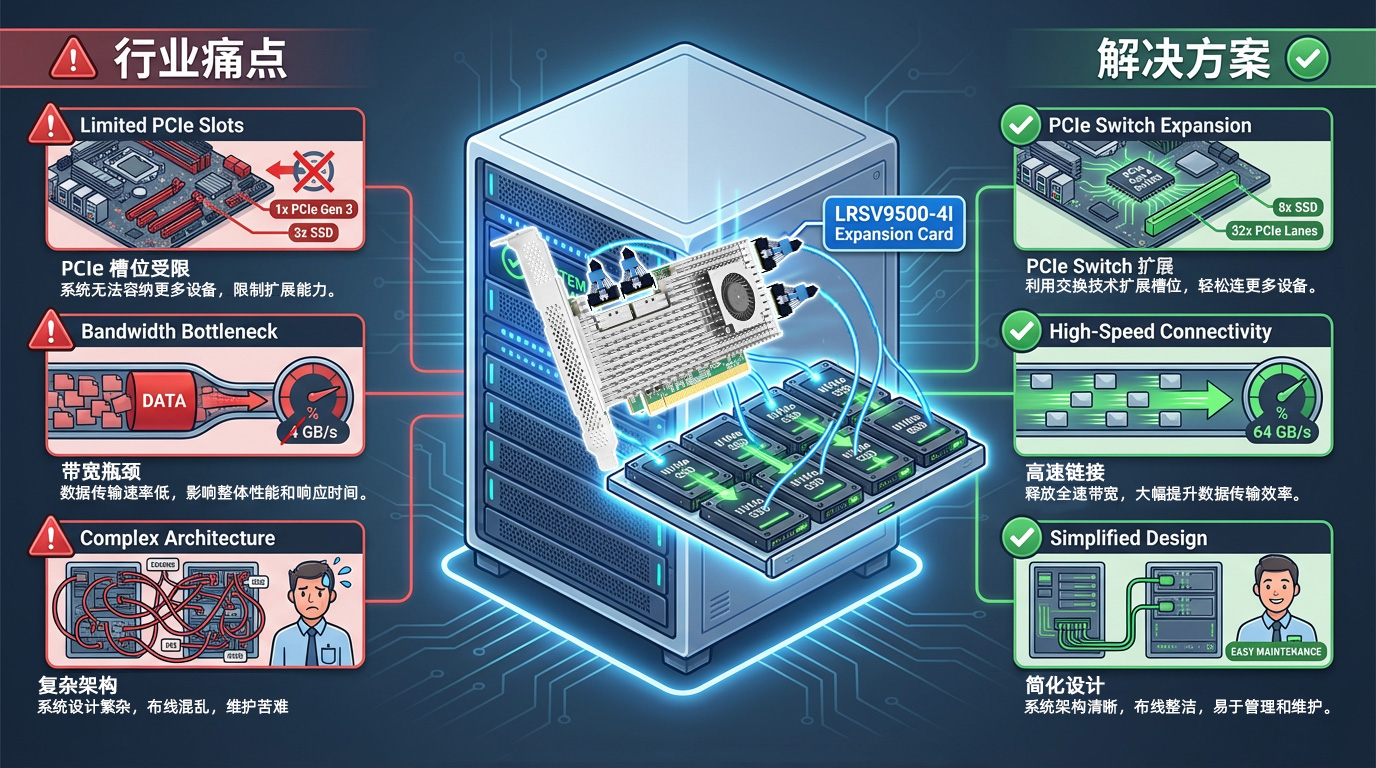
最近のサーバー用マザーボードには通常、4~8個のPCIeスロットしか搭載されておらず、これらでネットワークカード、GPU、NVMe SSD、RAIDカードなど、さまざまな周辺機器の要件を同時に満たす必要があります。 AIトレーニングのシナリオでは、1台のサーバーに4~8枚のGPUグラフィックスカードに加え、高速ストレージデバイスが必要となる場合があり、PCIeスロットの数が最大の制約要因となることがよくあります。
1.2 事業への影響
GPUとSSDを同時に導入するのは難しく、演算能力とストレージ容量の間で妥協が必要となる
企業はより多くのサーバーを購入せざるを得ず、その結果、TCOが大幅に増加することになる
キャビネットの空き容量はすぐに埋まってしまうため、データセンターのリソース利用率が低下している
1.3 LRSV9500-4I ソリューション
Broadcom PEX89048 PCIeスイッチチップを搭載したLRSV9500-4Iは、1つのPCIe GEN 5.0 x16スロットを4つのMCIO 8Iインターフェースに拡張します。 これにより、8台のNVMe SSDをX4モードで、2枚のハイエンドGPUグラフィックスカードをX16モードで接続可能です。占有するPCIeスロットは1つだけで、拡張効率を800%向上させます。
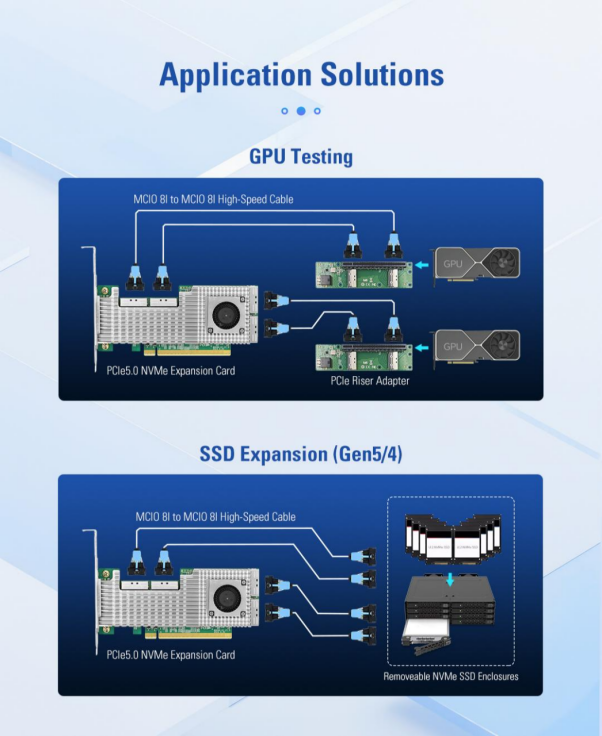
AIトレーニング環境では、GPUと高速ストレージの両方に極めて高い要件が課されます。GPUは膨大な量のデータを処理する必要がありますが、従来のSAS/SATAストレージの帯域幅やIOPSではその需要を満たすことができません。しかし、マザーボード上のPCIeスロットがGPUで埋まってしまうと、NVMe SSDアレイを導入するためのインターフェースが不足してしまいます。
· 大規模モデルの学習中、GPUの計算能力の利用率は通常、ピーク時の計算能力を下回ります。例えば、1000台のGPUクラスターでは利用率が約59%、10000台のGPUクラスターでは約55.2%となります。
· トレーニングデータの読み込みがボトルネックとなり、モデルの反復サイクルが長引く
X8ハイブリッドモードにより、LRSV9500-4IはGPUとNVMe SSDを同時にサポートできます。 例えば、2×X8をGPUの接続に使い、残りの2×X8をローカルキャッシュとして2台のNVMe SSDに接続します。これにより、GPUは高速なローカルストレージから直接データを読み取ることができ、トレーニング効率を3~5倍向上させることができます。
PCIe 5.0規格の信号伝送速度は32GT/sに達します。この2倍の速度は、データ伝送の正確性と効率性を確保するために、信号の完全性に対して極めて厳しい要件を課すことになります。長距離伝送や、品質の劣るケーブルやコネクタを使用すると、信号の減衰やビットエラー率の上昇を招き、深刻な場合には機器が認識されなくなったり、頻繁に接続が切断されたりする原因となります。
· GPUトレーニングの最中にカードが外れてしまうと、数日分の計算結果が失われてしまいます
· ストレージデバイスの動作速度が低下し、PCIe 5.0から4.0、あるいは3.0にまで低下します
· システムの不安定化やブルースクリーンが発生し、業務の継続性に影響を及ぼす
LRSV9500-4Iは、高スペックのPCB設計、高品質なコネクタ、および信号最適化技術を採用し、PCIe 5.0のフルレートでの安定した動作を保証します。 PCIe 5.0技術は、適切な構成下で最大14,000MB/sのシーケンシャル読み取り・書き込み速度と最適なパフォーマンスを実現します。MCIOインターフェースは信頼性の高い物理接続を提供し、認定ケーブルと組み合わせることで、ビットエラー率を効果的に低減し、24時間365日の安定した動作を保証します。
マルチGPUトレーニング環境において、GPU間の相互接続トポロジーはトレーニング効率に直接影響を及ぼします。従来のソリューションはCPUが提供するPCIeチャネルに依存しており、複数のGPUカード間の通信はCPUを経由する必要があるため、帯域幅が制限され、レイテンシが高くなってしまいます。
· GPU間の通信帯域幅が不十分なため、分散トレーニングの効率は低い
· 大規模なクラスタ拡張において課題が生じている
X16モードでは、LRSV9500-4Iにより、GPUがスイッチを介して効率的なP2P通信を実現し、マルチカードトレーニングの効率を効果的に向上させます。
ホスト間クラスタの場合、RoCE v2(RDMA over Converged Ethernet)に対応したネットワークカードを利用することで、GPUはCPUを経由せずに、ネットワークアダプタを介してリモートGPUのビデオメモリに直接データを書き込むことができます。複数のサーバーが直接相互接続され、メモリ共有と高速なデータ交換が実現されます。
サーバーのGPUおよびストレージ拡張における課題は、本質的に、限られたリソースと無限の需要との間の矛盾にあります。 PCIeスイッチ技術と柔軟なX4/X8/X16バイファケーションモードにより、LRSV9500-4Iは企業に効率的なソリューションパスを提供します。AIトレーニング、ハイパフォーマンスコンピューティング、ビッグデータ分析、あるいは映像制作のいずれにおいても、 LRSV9500-4I 優れた拡張性と投資保護を実現できます。
LR-LINKのPCIe 5.0分野におけるフラッグシップ製品であるLRSV9500-4Iは、Broadcom PEX89048チップの卓越した性能と充実したエコシステムサポートを基盤として、AIサーバーおよびデータセンター構築において最適な拡張ソリューションとして注目を集めています。 LRSV9500-4Iを選択することは、柔軟性、効率性、そして将来性を兼ね備えた拡張アーキテクチャを選択することを意味します。






