
Avec le développement rapide de l'entraînement des grands modèles d'IA, du calcul haute performance et du cloud computing, la demande des entreprises en matière de puissance de calcul GPU et de performances de stockage des serveurs a connu une croissance explosive. Cependant, les architectures de serveurs traditionnelles présentent de nombreux goulots d'étranglement en matière de capacités d'extension, tels que le nombre limité d'emplacements PCIe, la difficulté à équilibrer le déploiement des GPU et des SSD, ainsi que le manque de flexibilité des solutions d'extension. Ces problèmes ont fortement freiné l'innovation dans les entreprises. Cet article analyse en profondeur ces points faibles du secteur et démontre comment LR-LINK LRSV9500-4I offre aux entreprises une solution d'extension tout-en-un grâce à des modes de bifurcation flexibles X4/X8/X16.
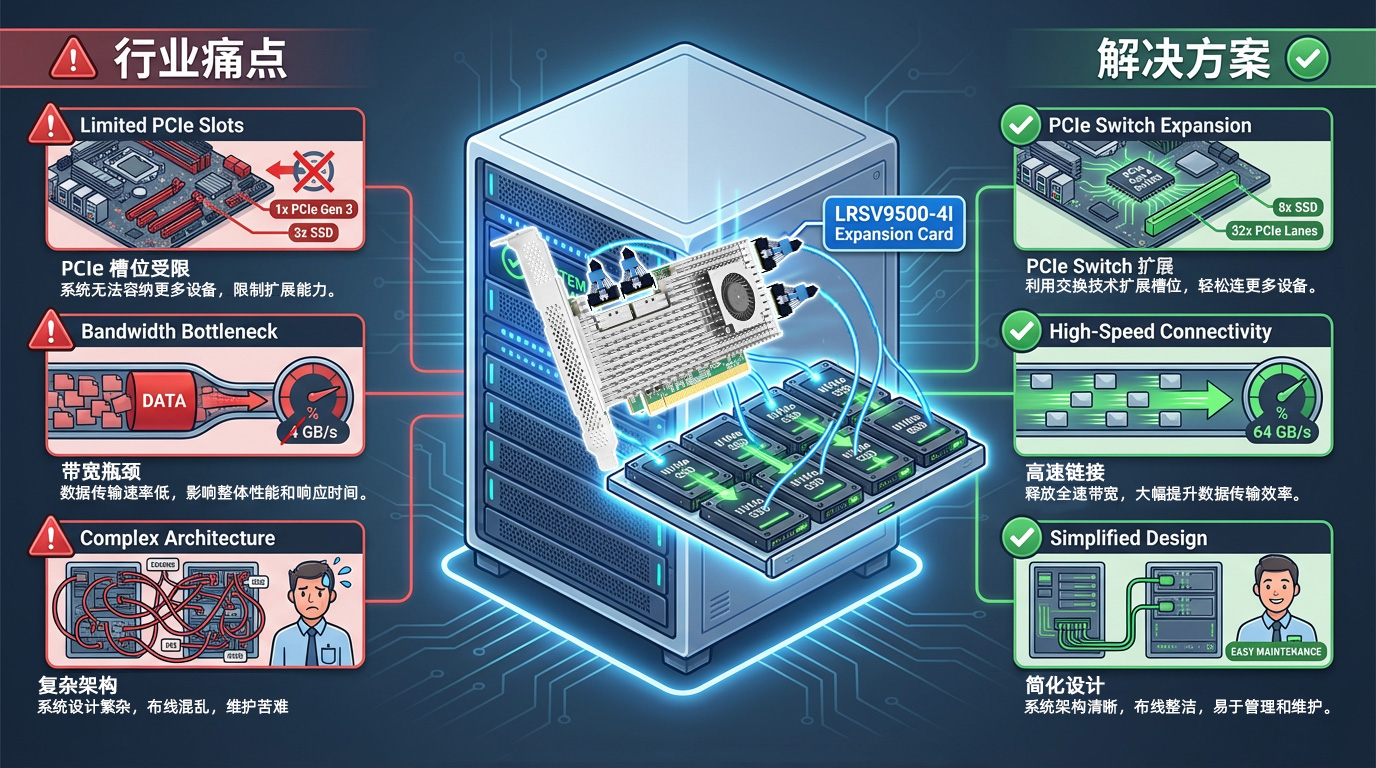
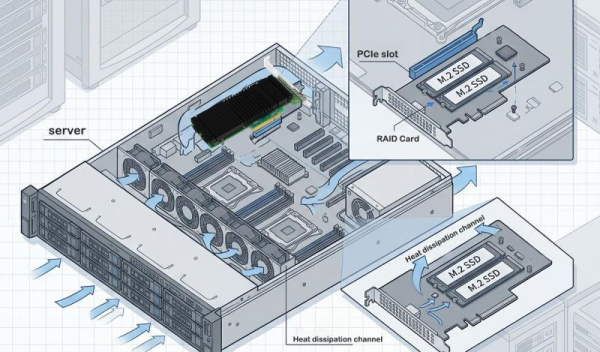
I. Pénurie grave de ressources de slots PCIe
1.1 Situation actuelle
Les cartes mères de serveurs modernes ne disposent généralement que de 4 à 8 emplacements PCIe, qui doivent répondre simultanément aux besoins de divers périphériques tels que les cartes réseau, les GPU, les SSD NVMe et les cartes RAID. Dans les scénarios d'entraînement IA, un seul serveur peut nécessiter 4 à 8 cartes graphiques GPU, ainsi que des périphériques de stockage haut débit, ce qui fait que le nombre d'emplacements PCIe constitue souvent la principale contrainte.
1.2 Conséquences sur l'activité
Il est difficile de déployer simultanément un GPU et un SSD, et il faut trouver un compromis entre la puissance de calcul et le stockage
Les entreprises doivent acheter davantage de serveurs, ce qui entraîne une augmentation considérable du coût total de possession
L'espace dans les armoires s'épuise rapidement, ce qui entraîne une faible utilisation des ressources des centres de données
1.3 Solution LRSV9500-4I
Basé sur la puce de commutation PCIe Broadcom PEX89048, le LRSV9500-4I permet de transformer un seul emplacement PCIe GEN 5.0 x16 en 4 interfaces MCIO 8I. Il permet de connecter 8 SSD NVMe en mode X4 et 2 cartes graphiques GPU haut de gamme en mode X16. Un seul emplacement PCIe est occupé, ce qui se traduit par une amélioration de 800 % de l'efficacité d'extension.
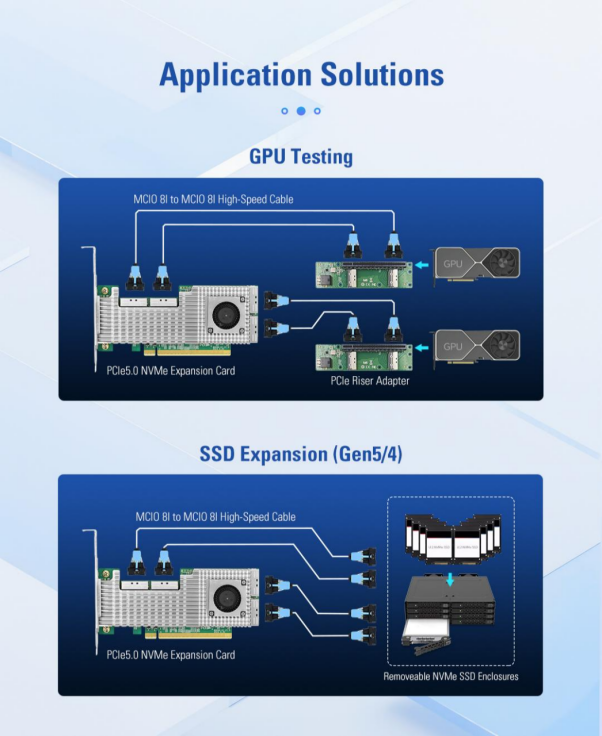
Les scénarios d'entraînement de l'IA imposent des exigences extrêmement élevées tant au niveau des GPU que du stockage haut débit. Les GPU doivent traiter d'énormes volumes de données, tandis que la bande passante et les IOPS des systèmes de stockage SAS/SATA traditionnels ne suffisent pas à répondre à la demande. Cependant, une fois que les emplacements PCIe de la carte mère sont occupés par les GPU, il ne reste plus suffisamment d'interfaces pour déployer des baies de SSD NVMe.
· Lors de l'entraînement de modèles volumineux, le taux d'utilisation de la puissance de calcul des GPU est généralement inférieur à la puissance de calcul maximale. Par exemple, ce taux est d'environ 59 % dans un cluster de 1 000 GPU et d'environ 55,2 % dans un cluster de 10 000 GPU.
· La lecture des données d'entraînement devient un facteur limitant, ce qui allonge les cycles d'itération du modèle
Grâce au mode hybride X8, le LRSV9500-4I peut prendre en charge simultanément un GPU et un SSD NVMe. Par exemple, 2×X8 sont utilisés pour connecter des GPU, et les 2×X8 restants sont connectés à 2 SSD NVMe servant de cache local. De cette manière, les GPU peuvent lire les données directement à partir d'un stockage local à haute vitesse, ce qui améliore l'efficacité de l'entraînement de 3 à 5 fois.
Le débit de signal de la norme PCIe 5.0 atteint 32 GT/s. Ce doublement de la vitesse impose des exigences extrêmement strictes en matière d'intégrité du signal afin de garantir la précision et l'efficacité de la transmission des données. Une transmission sur de longues distances, des câbles ou des connecteurs de mauvaise qualité entraîneront une atténuation du signal et une augmentation du taux d'erreurs sur les bits ; dans les cas les plus graves, les équipements ne pourront pas être identifiés ou subiront des déconnexions fréquentes.
· Si une carte est déconnectée pendant le processus d'entraînement du GPU, plusieurs jours de résultats de calcul seront perdus
· Les périphériques de stockage fonctionnent à une vitesse réduite, passant de PCIe 5.0 à 4.0, voire à 3.0
· Des problèmes d'instabilité du système et des écrans bleus apparaissent, ce qui nuit à la continuité des activités
Le LRSV9500-4I intègre une conception de circuit imprimé haut de gamme, des connecteurs de qualité supérieure et une technologie d'optimisation du signal afin de garantir un fonctionnement stable du PCIe 5.0 à pleine vitesse. La technologie PCIe 5.0 peut offrir des vitesses de lecture et d'écriture séquentielles allant jusqu'à 14 000 Mo/s et des performances optimales lorsqu'elle est correctement configurée. L'interface MCIO assure une connexion physique fiable et, avec des câbles certifiés, permet de réduire efficacement le taux d'erreurs sur les bits et de garantir un fonctionnement stable 24 heures sur 24, 7 jours sur 7.
Dans les scénarios d'entraînement multi-GPU, la topologie d'interconnexion entre les GPU a une incidence directe sur l'efficacité de l'entraînement. Les solutions traditionnelles s'appuient sur les canaux PCIe fournis par le CPU, et la communication entre plusieurs cartes doit passer par le CPU, ce qui se traduit par une bande passante limitée et une latence élevée.
· L'efficacité de l'entraînement distribué est faible en raison d'une bande passante de communication insuffisante entre les GPU
· L'expansion de clusters à grande échelle se heurte à des difficultés
En mode X16, le LRSV9500-4I permet aux GPU d'établir une communication P2P efficace via le commutateur, améliorant ainsi considérablement l'efficacité de l'entraînement multi-cartes.
Dans le cas des clusters inter-serveurs, grâce à des cartes réseau prenant en charge le protocole RoCE v2 (RDMA over Converged Ethernet), les GPU peuvent contourner le CPU et écrire directement des données dans la mémoire vidéo de GPU distants via la carte réseau. Plusieurs serveurs sont directement interconnectés afin de permettre le partage de mémoire et l'échange de données à haut débit.
Les principaux défis liés à l'extension des capacités de stockage et des GPU sur les serveurs tiennent essentiellement à la contradiction entre des ressources limitées et une demande illimitée. Grâce à la technologie de commutateur PCIe et aux modes de bifurcation flexibles X4/X8/X16, le LRSV9500-4I offre aux entreprises une solution efficace. Que ce soit pour l'entraînement de l'IA, le calcul haute performance, l'analyse de mégadonnées ou la production vidéo, LRSV9500-4I peut offrir d'excellentes possibilités d'extension et garantir la protection de votre investissement.
En tant que produit phare de LR-LINK dans le domaine du PCIe 5.0, le LRSV9500-4I, qui s'appuie sur les performances de pointe de la puce Broadcom PEX89048 et sur une prise en charge parfaite de l'écosystème, s'impose comme la solution d'extension privilégiée pour la construction de serveurs IA et de centres de données. Choisir le LRSV9500-4I, c'est opter pour une architecture d'extension flexible, efficace et tournée vers l'avenir.






