
Con el rápido desarrollo del entrenamiento de grandes modelos de IA, la computación de alto rendimiento y la computación en la nube, la demanda de las empresas en cuanto a potencia de cálculo de GPU en servidores y rendimiento de almacenamiento ha experimentado un crecimiento explosivo. Sin embargo, las arquitecturas de servidor tradicionales presentan numerosos cuellos de botella en cuanto a capacidad de expansión, como el número limitado de ranuras PCIe, la dificultad para equilibrar la implementación de GPU y SSD, y la falta de flexibilidad en las soluciones de expansión. Estos problemas han limitado gravemente la innovación empresarial. En este artículo se analizarán en profundidad estos puntos débiles del sector y se demostrará cómo LR-LINK LRSV9500-4I ofrece a las empresas una solución integral de ampliación mediante los modos flexibles de bifurcación X4/X8/X16.
I. Grave escasez de ranuras PCIe
1.1 Situación actual
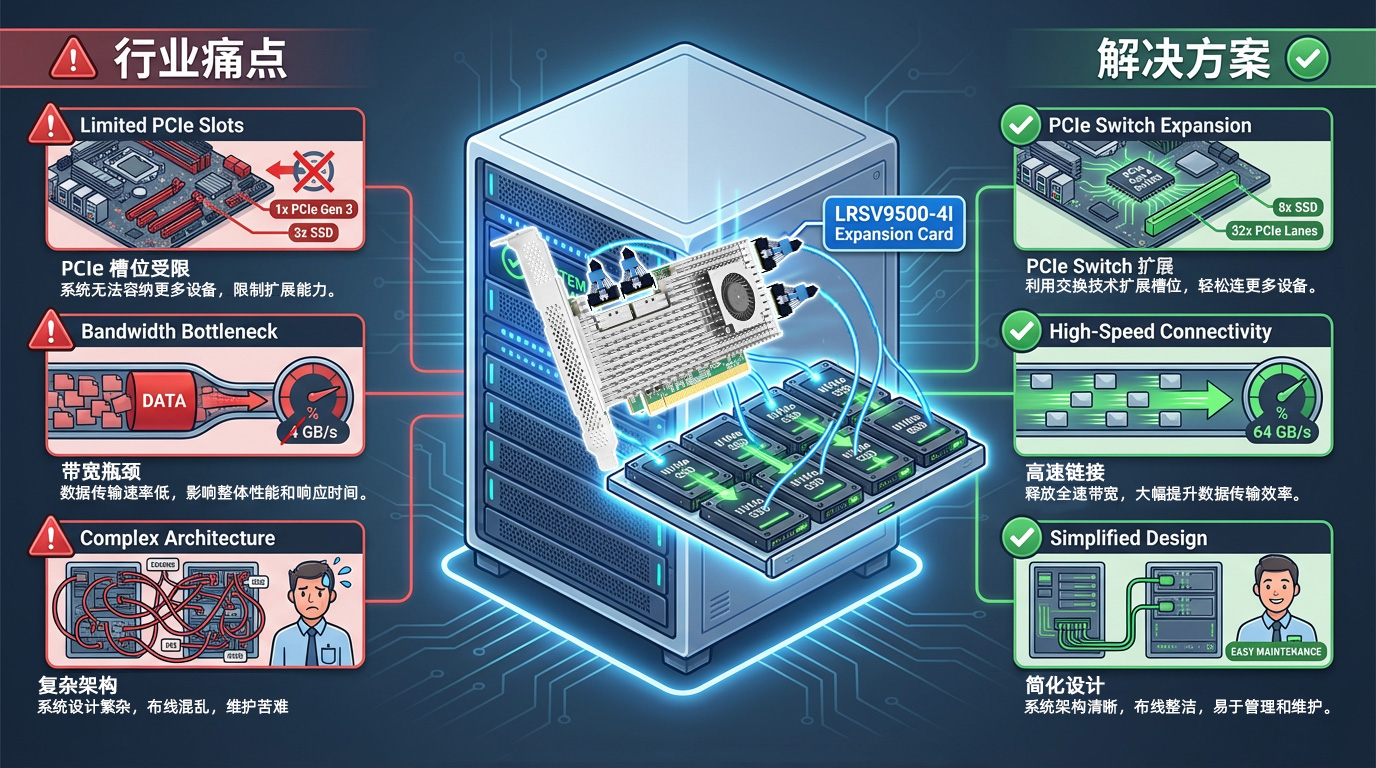
Las placas base de los servidores modernos suelen ofrecer solo entre 4 y 8 ranuras PCIe, que deben satisfacer al mismo tiempo las necesidades de diversos periféricos, como tarjetas de red, GPU, unidades SSD NVMe y tarjetas RAID. En entornos de entrenamiento de IA, un solo servidor puede requerir de 4 a 8 tarjetas gráficas GPU, además de dispositivos de almacenamiento de alta velocidad, lo que hace que el número de ranuras PCIe sea a menudo la mayor limitación.
1.2 Repercusiones en la empresa
Es difícil implementar una GPU y un SSD al mismo tiempo, por lo que hay que encontrar un equilibrio entre la potencia de cálculo y el almacenamiento
Las empresas se ven obligadas a adquirir más servidores, lo que conlleva un aumento significativo del coste total de propiedad
El espacio en los armarios se agota rápidamente, lo que da lugar a una baja utilización de los recursos de los centros de datos
1.3 Solución LRSV9500-4I
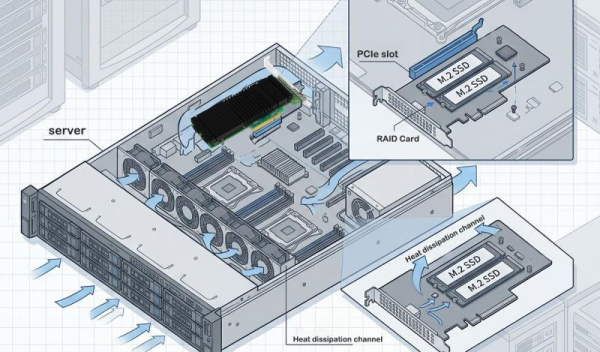
Basado en el chip de conmutador PCIe PEX89048 de Broadcom, el LRSV9500-4I amplía una única ranura PCIe GEN 5.0 x16 a 4 interfaces MCIO 8I. Permite conectar 8 SSD NVMe en modo X4 y 2 tarjetas gráficas GPU de gama alta en modo X16. Solo se ocupa una ranura PCIe, lo que supone una mejora del 800 % en la eficiencia de expansión.
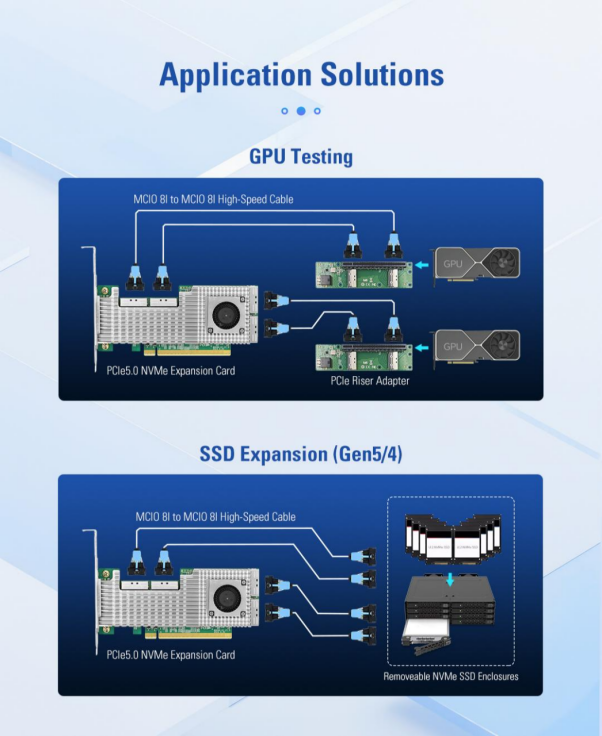
Los entornos de entrenamiento de IA plantean requisitos extremadamente exigentes tanto para las GPU como para el almacenamiento de alta velocidad. Las GPU deben procesar enormes cantidades de datos, mientras que el ancho de banda y las IOPS del almacenamiento SAS/SATA tradicional no pueden satisfacer esa demanda. Sin embargo, una vez que las ranuras PCIe de la placa base están ocupadas por las GPU, no quedan interfaces suficientes para implementar matrices de SSD NVMe.
· Durante el entrenamiento de modelos de gran tamaño, la tasa de utilización de la potencia de cálculo de las GPU suele ser inferior a la potencia máxima de cálculo. Por ejemplo, la tasa de utilización es de aproximadamente el 59 % en un clúster de 1000 GPU y de aproximadamente el 55,2 % en un clúster de 10 000 GPU.
· La lectura de los datos de entrenamiento se convierte en un factor limitante, lo que da lugar a ciclos de iteración del modelo más largos
Gracias al modo híbrido X8, el LRSV9500-4I puede admitir simultáneamente una GPU y un SSD NVMe. Por ejemplo, se utilizan 2×X8 para conectar las GPU, y los 2×X8 restantes se conectan a 2 SSD NVMe como caché local. De esta forma, las GPU pueden leer datos directamente desde el almacenamiento local de alta velocidad, lo que mejora la eficiencia del entrenamiento entre 3 y 5 veces.
La velocidad de señal del estándar PCIe 5.0 alcanza los 32 GT/s. Esta velocidad duplicada implica unos requisitos extremadamente estrictos en materia de integridad de la señal para garantizar la precisión y la eficiencia de la transmisión de datos. La transmisión a larga distancia, el uso de cables o conectores de baja calidad provocarán una atenuación de la señal y un aumento de la tasa de errores de bits y, en casos graves, los equipos no podrán identificarse o se desconectarán con frecuencia.
· Durante el proceso de entrenamiento de la GPU, si se desconecta una tarjeta, se perderán los resultados de varios días de cálculo
· Los dispositivos de almacenamiento funcionan a una velocidad reducida, pasando de PCIe 5.0 a 4.0, o incluso a 3.0
· Se producen inestabilidades del sistema y pantallas azules de la muerte, lo que afecta a la continuidad del negocio
El LRSV9500-4I incorpora un diseño de placa de circuito impreso de alta especificación, conectores de alta calidad y tecnología de optimización de la señal para garantizar el funcionamiento estable de PCIe 5.0 a velocidad máxima. La tecnología PCIe 5.0 puede proporcionar velocidades de lectura y escritura secuenciales de hasta 14 000 MB/s y un rendimiento óptimo con la configuración adecuada. La interfaz MCIO proporciona una conexión física fiable y, con cables certificados, puede reducir eficazmente la tasa de error de bits y garantizar un funcionamiento estable las 24 horas del día, los 7 días de la semana.
En entornos de entrenamiento con múltiples GPU, la topología de interconexión entre las GPU influye directamente en la eficiencia del entrenamiento. Las soluciones tradicionales se basan en los canales PCIe que proporciona la CPU, y la comunicación entre varias tarjetas debe pasar por la CPU, lo que da lugar a un ancho de banda limitado y a una latencia elevada.
· La eficiencia del entrenamiento distribuido es baja debido a un ancho de banda de comunicación insuficiente entre las GPU
· Se plantean dificultades en la expansión de clústeres a gran escala
En el modo X16, el LRSV9500-4I permite que las GPU establezcan una comunicación P2P eficiente a través del conmutador, lo que mejora de forma efectiva la eficiencia del entrenamiento con varias tarjetas.
En el caso de los clústeres entre hosts, gracias a las tarjetas de red compatibles con RoCE v2 (RDMA sobre Ethernet convergente), las GPU pueden eludir la CPU y escribir datos directamente en la memoria de vídeo de las GPU remotas a través del adaptador de red. Varios servidores se interconectan directamente para lograr el uso compartido de memoria y el intercambio de datos a alta velocidad.
Los principales retos de la ampliación de la capacidad de almacenamiento y de las GPU de los servidores radican, en esencia, en la contradicción entre unos recursos limitados y una demanda ilimitada. Gracias a la tecnología de conmutador PCIe y a los modos flexibles de bifurcación X4/X8/X16, el LRSV9500-4I ofrece a las empresas una solución eficiente. Ya sea para el entrenamiento de IA, la computación de alto rendimiento, el análisis de big data o la producción de vídeo, LRSV9500-4I puede ofrecer excelentes posibilidades de expansión y protección de la inversión.
Como producto estrella de LR-LINK en el ámbito del PCIe 5.0, el LRSV9500-4I, gracias al rendimiento puntero del chip Broadcom PEX89048 y a su perfecta compatibilidad con el ecosistema, se está convirtiendo en la solución de expansión preferida para la construcción de servidores de IA y centros de datos. Elegir el LRSV9500-4I significa optar por una arquitectura de expansión flexible, eficiente y orientada al futuro.






