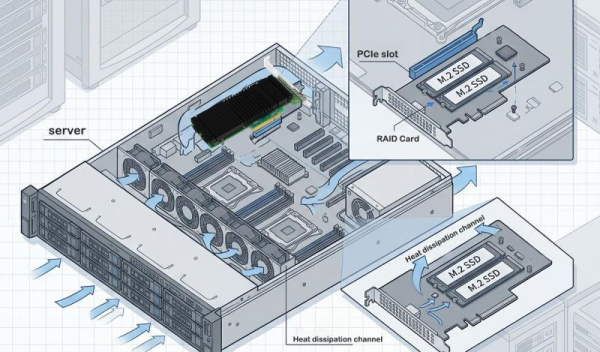

Với sự phát triển nhanh chóng của việc huấn luyện các mô hình AI quy mô lớn, tính toán hiệu suất cao và điện toán đám mây, nhu cầu của các doanh nghiệp về sức mạnh tính toán GPU trên máy chủ và hiệu suất lưu trữ đã cho thấy xu hướng tăng trưởng bùng nổ. Tuy nhiên, các kiến trúc máy chủ truyền thống gặp nhiều hạn chế về khả năng mở rộng, chẳng hạn như số khe cắm PCIe hạn chế, khó khăn trong việc cân bằng việc triển khai GPU và SSD, cũng như thiếu tính linh hoạt trong các giải pháp mở rộng. Những vấn đề này đã hạn chế nghiêm trọng sự đổi mới trong kinh doanh. Bài viết này sẽ phân tích sâu các điểm khó khăn của ngành và trình bày cách LR-LINK LRSV9500-4I cung cấp cho các doanh nghiệp giải pháp mở rộng toàn diện thông qua các chế độ phân nhánh linh hoạt X4/X8/X16.
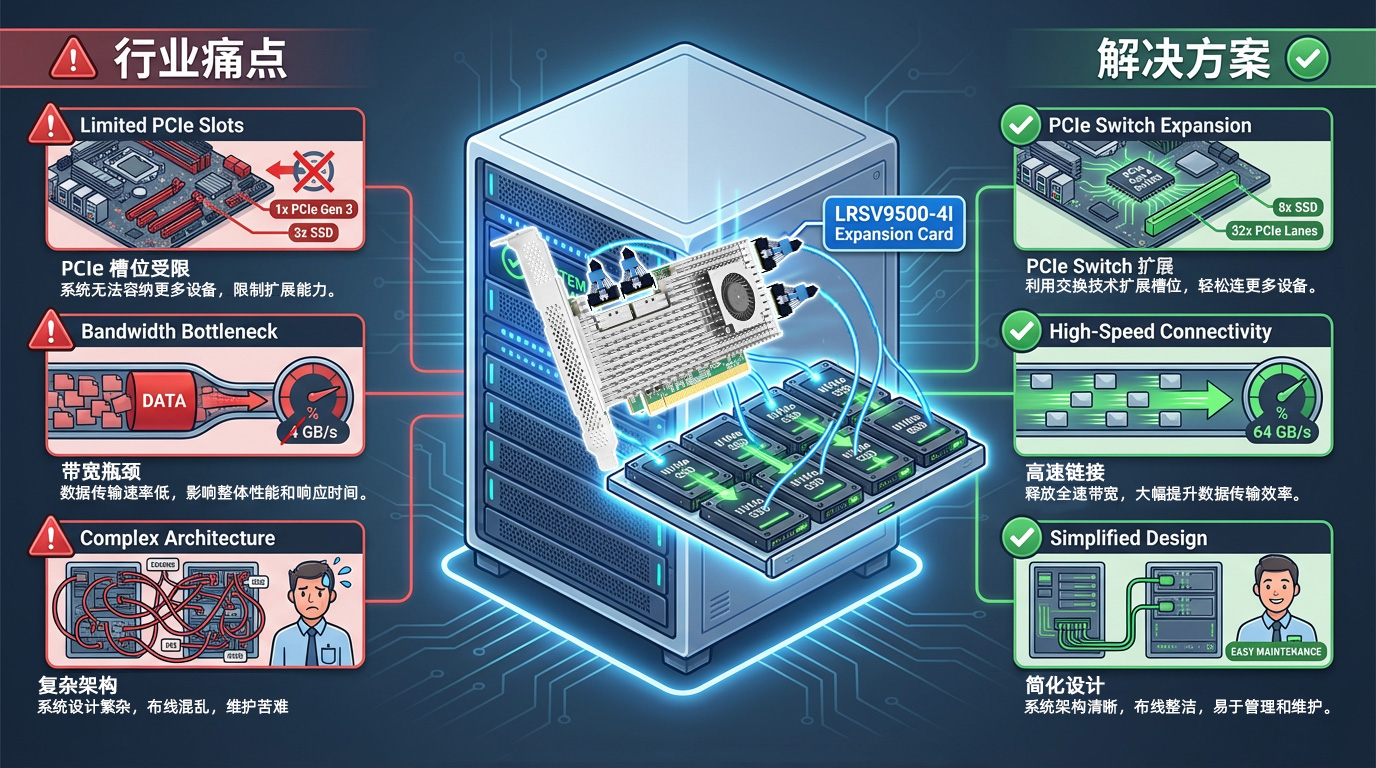
I. Tình trạng thiếu hụt nghiêm trọng tài nguyên khe cắm PCIe
1.1 Tình hình hiện nay
Các bo mạch chủ máy chủ hiện đại thường chỉ cung cấp từ 4 đến 8 khe cắm PCIe, vốn phải đáp ứng đồng thời các yêu cầu của nhiều thiết bị ngoại vi khác nhau như card mạng, GPU, ổ SSD NVMe và card RAID. Trong các tình huống đào tạo AI, một máy chủ có thể cần từ 4 đến 8 card đồ họa GPU, cộng với các thiết bị lưu trữ tốc độ cao, khiến số lượng khe cắm PCIe thường trở thành hạn chế lớn nhất.
1.2 Tác động đến hoạt động kinh doanh
Việc triển khai đồng thời GPU và SSD là điều khó khăn, và cần phải cân nhắc giữa hiệu năng tính toán và dung lượng lưu trữ
Các doanh nghiệp phải mua thêm máy chủ, dẫn đến chi phí sở hữu tổng thể (TCO) tăng đáng kể
Dung lượng lưu trữ bị cạn kiệt nhanh chóng, dẫn đến tình trạng sử dụng tài nguyên của các trung tâm dữ liệu không hiệu quả
1.3 Giải pháp LRSV9500-4I
Dựa trên chip chuyển mạch PCIe Broadcom PEX89048, LRSV9500-4I mở rộng một khe cắm PCIe GEN 5.0 x16 thành 4 giao diện MCIO 8I. Thiết bị này có thể kết nối 8 ổ SSD NVMe ở chế độ X4 và 2 card đồ họa GPU cao cấp ở chế độ X16. Chỉ chiếm dụng một khe cắm PCIe, giúp nâng cao hiệu quả mở rộng lên đến 800%.
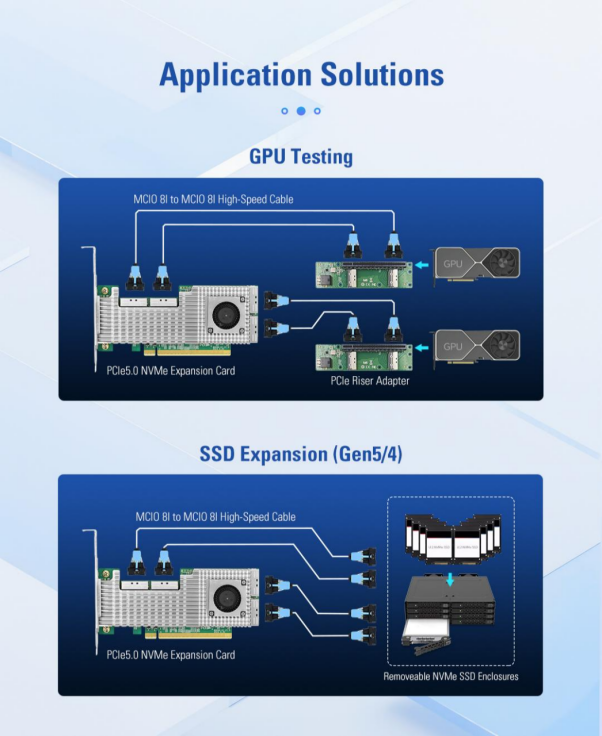
Các kịch bản huấn luyện AI đặt ra những yêu cầu cực kỳ cao đối với cả GPU lẫn thiết bị lưu trữ tốc độ cao. GPU cần xử lý khối lượng dữ liệu khổng lồ, trong khi băng thông và IOPS của các thiết bị lưu trữ SAS/SATA truyền thống không thể đáp ứng được nhu cầu này. Tuy nhiên, sau khi các khe cắm PCIe trên bo mạch chủ đã bị chiếm dụng bởi GPU, sẽ không còn đủ cổng kết nối để triển khai các mảng ổ SSD NVMe.
· Trong quá trình huấn luyện các mô hình quy mô lớn, tỷ lệ sử dụng công suất tính toán của GPU thường thấp hơn công suất tính toán tối đa. Ví dụ, tỷ lệ sử dụng này vào khoảng 59% trong một cụm 1.000 GPU và khoảng 55,2% trong một cụm 10.000 GPU.
· Việc đọc dữ liệu huấn luyện trở thành một yếu tố hạn chế, dẫn đến các chu kỳ lặp mô hình kéo dài hơn
Thông qua chế độ lai X8, LRSV9500-4I có thể hỗ trợ đồng thời cả GPU và SSD NVMe. Ví dụ, 2×X8 được sử dụng để kết nối GPU, và 2×X8 còn lại được kết nối với 2 ổ SSD NVMe làm bộ nhớ đệm cục bộ. Nhờ đó, GPU có thể đọc dữ liệu trực tiếp từ bộ nhớ cục bộ tốc độ cao, giúp nâng cao hiệu quả đào tạo lên 3 đến 5 lần.
Tốc độ tín hiệu của tiêu chuẩn PCIe 5.0 đạt 32GT/s. Tốc độ gấp đôi này đặt ra những yêu cầu cực kỳ khắt khe về tính toàn vẹn tín hiệu nhằm đảm bảo độ chính xác và hiệu quả của quá trình truyền dữ liệu. Việc truyền dẫn trên khoảng cách xa, sử dụng cáp hoặc đầu nối kém chất lượng sẽ dẫn đến hiện tượng suy giảm tín hiệu và làm tăng tỷ lệ lỗi bit; trong những trường hợp nghiêm trọng, thiết bị có thể không được nhận diện hoặc thường xuyên bị ngắt kết nối.
· Trong quá trình huấn luyện GPU, nếu một chiếc card bị ngắt kết nối, kết quả tính toán của nhiều ngày sẽ bị mất
· Các thiết bị lưu trữ hoạt động ở tốc độ thấp hơn, từ PCIe 5.0 xuống còn 4.0, hoặc thậm chí là 3.0
· Hệ thống gặp sự cố mất ổn định và xuất hiện màn hình xanh chết chóc, từ đó ảnh hưởng đến sự liên tục của hoạt động kinh doanh
LRSV9500-4I áp dụng thiết kế PCB cao cấp, các đầu nối chất lượng cao và công nghệ tối ưu hóa tín hiệu để đảm bảo hoạt động ổn định của PCIe 5.0 ở tốc độ tối đa. Công nghệ PCIe 5.0 có thể cung cấp tốc độ đọc và ghi tuần tự lên đến 14.000MB/s và hiệu suất tối ưu khi được cấu hình đúng cách. Giao diện MCIO cung cấp kết nối vật lý đáng tin cậy, và khi sử dụng cáp được chứng nhận, nó có thể giảm hiệu quả tỷ lệ lỗi bit và đảm bảo hoạt động ổn định 24/7.
Trong các kịch bản huấn luyện đa GPU, cấu trúc kết nối giữa các GPU ảnh hưởng trực tiếp đến hiệu quả huấn luyện. Các giải pháp truyền thống dựa vào các kênh PCIe do CPU cung cấp, và việc giao tiếp giữa các thẻ đồ họa phải đi qua CPU, dẫn đến băng thông bị hạn chế và độ trễ cao.
· Hiệu quả của phương pháp huấn luyện phân tán thấp do băng thông truyền thông giữa các GPU không đủ
· Việc mở rộng cụm quy mô lớn gặp phải một số khó khăn
Ở chế độ X16, LRSV9500-4I cho phép các GPU thực hiện giao tiếp ngang hàng (P2P) hiệu quả thông qua bộ chuyển mạch, từ đó nâng cao hiệu quả của quá trình huấn luyện đa card.
Đối với các cụm máy chủ liên kết, nhờ sự hỗ trợ của các thẻ mạng tương thích với RoCE v2 (RDMA qua mạng Ethernet hội tụ), các GPU có thể bỏ qua CPU và ghi dữ liệu trực tiếp vào bộ nhớ đồ họa của các GPU từ xa thông qua bộ điều hợp mạng. Nhiều máy chủ được kết nối trực tiếp với nhau để thực hiện chia sẻ bộ nhớ và trao đổi dữ liệu tốc độ cao.
Những thách thức trong việc mở rộng GPU và bộ nhớ lưu trữ cho máy chủ về cơ bản xuất phát từ mâu thuẫn giữa nguồn lực hạn chế và nhu cầu không ngừng gia tăng. Thông qua công nghệ PCIe Switch và các chế độ phân nhánh linh hoạt X4/X8/X16, LRSV9500-4I mang đến cho các doanh nghiệp một giải pháp hiệu quả. Dù là cho đào tạo AI, tính toán hiệu suất cao, phân tích dữ liệu lớn hay sản xuất video, LRSV9500-4I có thể mang lại khả năng mở rộng tuyệt vời và bảo vệ vốn đầu tư.
Là sản phẩm chủ lực của LR-LINK trong lĩnh vực PCIe 5.0, LRSV9500-4I, nhờ vào hiệu năng hàng đầu của chip Broadcom PEX89048 cùng sự hỗ trợ hoàn hảo từ hệ sinh thái, đang trở thành giải pháp mở rộng được ưa chuộng cho việc xây dựng máy chủ AI và trung tâm dữ liệu. Lựa chọn LRSV9500-4I đồng nghĩa với việc lựa chọn một kiến trúc mở rộng linh hoạt, hiệu quả và hướng tới tương lai.






